I've made use of Google's S2 library across a couple different jobs for various use cases. The C++ bindings are well-documented and very fast, in fact I found writing my own Python bindings allowed a few faster operations than using the Python library directly, for example generating a spanning set of cell IDs.
I find it liberating to not rely on a backend implementation of geospatial indexing, or rather being agnostic to backend, simply indexing very efficiently the 64-bit integers.
The hierarchical nature of the Hilbert curves means that the child cells contain the ID of the parent, and also fit perfectly into the parent. This is in contrast with H3 where you necessarily cannot fit the 7 child hexagons into the parent without some overlap (see for example the logo on the H3 website https://eng.uber.com/h3/)
As a fun experiment, I wanted to use the library in Rust. While there isn't an official Rust port, I just used the library along with CXX (https://github.com/dtolnay/cxx) with a simple geospatial struct.
> Disclaimer ... This is not an official Google product.
What is an official Google product? What does it mean to be one? What should I understand from the presence or absence of this disclaimer? Probably some sort of SLO, but what precisely?
H3 has the significant downside that children nodes do not fit within parent nodes. So one needs to be very careful working within any sort of multi-resolution algorithm (the most effective uses I've seen are with a fixed resolution). S2 does not suffer from this.
Worth noting that this library is by the extraordinary genius Eric Veach, whose PhD thesis marked the beginning of modern rendering, besides also developing the core of Google's AdSense, and co-inventing jump consistent hash: https://arxiv.org/abs/1406.2294
As a geographer turned DS it is my duty to remind CS people that all geo methods are compromises. No system, s2, h3, mgrs, even lat lon are perfect for every project and you must think carefully about what you are doing and pick your geo representation based on your givens and druthers.
S2 wouldn't be a bad choice, it lets you compute "coverings" of arbitrary regions as S2 cells, with variable resolution. Fixed size is trickier but is probably doable, especially if you're allowed to null out unused cells. Check out https://s2.sidewalklabs.com/regioncoverer/
Let's say the land is confined to north America, the size can vary from an entire state to a single zip code (I know zips are logical addressing, not geological, but I have what I have), and the shape is unrestricted so it could be non-convex. I suppose one could convert various kinds of areas (states, cities, boroughs, ...) to lists of zipcodes contained within and OHE them but I feel like that would be the _worst_ solution.
Pokemon Go used (uses?) S2 for its coordinate system. I used it in a (now dead) location based mobile game and being able to locate proximal s2 cells at varying granularities was really cool.
> Why not project onto an ellipsoid? (The Earth isn’t quite ellipsoidal either, but it is even closer to being an ellipsoid than a sphere.) The answer relates to the other goals stated above, namely performance and robustness. Ellipsoidal operations are still orders of magnitude slower than the corresponding operations on a sphere. Furthermore, robust geometric algorithms require the implementation of exact geometric predicates that are not subject to numerical errors. While this is fairly straightforward for planar geometry, and somewhat harder for spherical geometry, it is not known how to implement all of the necessary predicates for ellipsoidal geometry.
Depends what you want to do. If you want to compute a few very precise bearings, distances, areas, etc. (say for some navigation or surveying application) you should use an ellipsoidal model or even something fancier if your requirements are very exacting. If you want to do computational geometry or spatial indexing with millions of objects, you might prefer to trade accuracy for speed and model with a sphere.
i was just starting a project and considering the use of s2. i'm going with geohash instead because I would get different values for the s2 cell based on implementation.
=> Cell: face 4, level 30, orientation 0, id 9868963757887927191
This discrepancy feels like it'd be some kind of signed/unsigned integer issue, but I didn't think that would be a thing in Ruby. It also doesn't seem like the level=1 cell value in Ruby would be such a large, specific number. I'm missing something.
For what it’s worth, at least in the case you described, it is indeed a case of signed vs unsigned representations. That is, the numbers
-8577780315821624425
and
9868963757887927191
have the exact same underlying 64-bit representation, which is all that matters for S2 (you can verify this by checking their difference is exactly 2^64). The former is just interpreting the 64-bit string as a signed int, while the latter is unsigned.
Separately, the level 1 number you mention
-8358680908399640576
is fairly simple if you look at its binary representation; almost all of its trailing digits are 0.
Basically, you really shouldn’t think of S2 values as integers, but more as their underlying length 64 bit string.
S2 cell IDs are usually uint64, so the Ruby version looks wrong. If you cast that int64 to uint64 you get the same value as the python version.
Level 1 IDs look like large random numbers in decimal, but when viewed in binary they have many trailing zeros, that are used to truncate to make the tokens.
"The reference implementation of the S2 library is written in C++. Versions in other languages are ported from the C++ code, and may not have the same robustness, performance, or features as the C++ version."
Astronomers have developed an indexing strategy using Hierarchical, Equal Area, and iso-Latitude Pixelisation (HEALPix): https://arxiv.org/abs/astro-ph/9905275
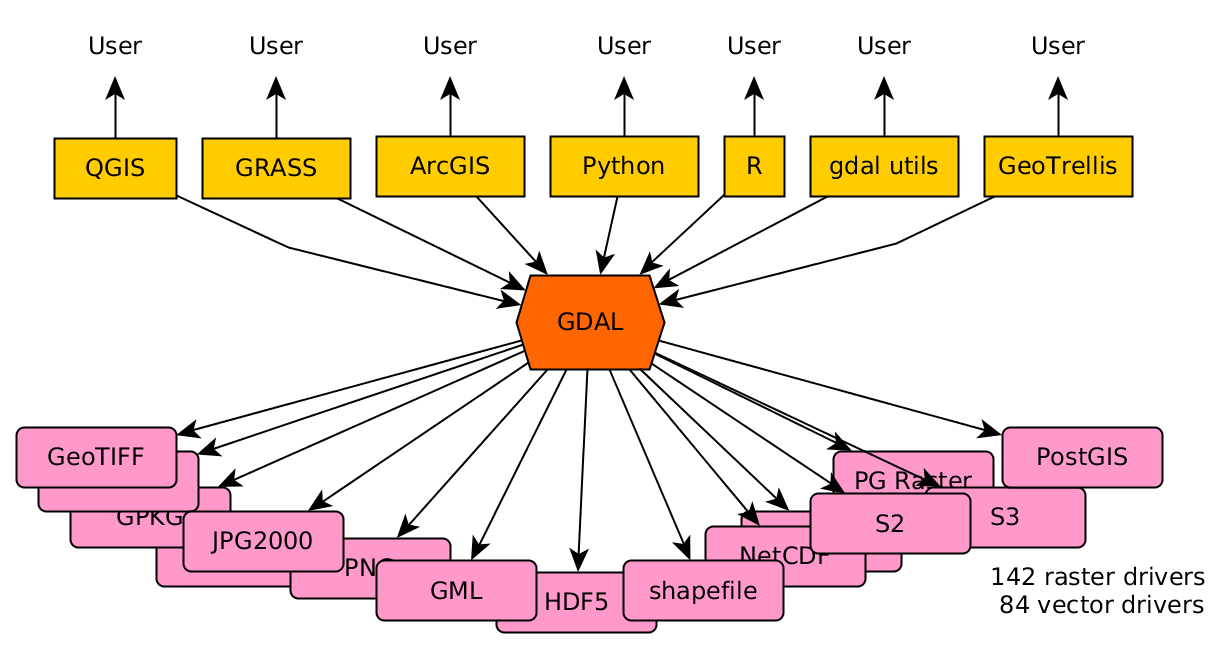
GDAL binary [0] uses a traditional C/C++ linked library architecture, and is extensible with plugin drivers; the memory model is therefore "local". A cloud architecture uses distributed resources.
Secondly, GDAL is tightly bound to Proj [1] for reprojecting spatial coordinates data from one spatial reference system (SRS) to another. The "sphere" libraries imply no generalized spatial reference, instead only a single spherical one.
More generally, gdal is a raster I/O library. S2 is a point only system. It's not meant to store or work with raster data in any way. (Sure, you can represent raster as points, but it's hideously inefficient to do so.)
Basically, you shouldn't ever be choosing between the two. If you're thinking of using a representation system like S2 for raster data (e.g. images or anything else on a regular grid), rethink things a bit.
Minor correction: S2's fundamental geometric types are points, edges, and S2 cells.
But your point about raster data is correct. If you're given a raster, like a satellite image, S2 has no built-in type to deal with it.
On the other hand, if you can define your own raster, like if you're making a heatmap or something and don't care about it being a lat-long aligned grid, you can use S2 cells like a raster, as they're roughly square and they tile the surface.
This is pretty common as it's fast and convenient. It has some advantages over lat-lng grids as well, because S2 cells are roughly equal in size across the whole surface of the sphere, while lat-long aligned pixels obviously get really warped near the poles, etc.
The issue with using S3 cells as a raster is the inefficiency in storing information.
You're basically making a row in a DB for every _pixel_ with the S2 approach.
The main point of raster storage is that it avoids the overhead associated with the "row for every datapoint" approach. E.g. the X and Y are implicit and it's simply a big array of Z values, then (optionally but commonly) a sequence of additional downsampled Z arrays for efficient lookup of low-res versions. These are typically tiled for efficiency of extraction of sub-regions. The simplest systems are flat pyramids of raster files in a bucket or on a filesystem. Things like tileDB are essentially a couple of layers on top of this type of idea. Either way, the basic unit is a few thousand pixels instead of 1 pixel, which is generally more efficient, as users are usually requesting millions of pixels.
A key advantage is that things are fundamentally in raster format and don't need to be translated back to raster format for the end user.
Basically, the requests / etc that wind up being made are for fundamentally pixels that are parallelograms of some sort in regions that are parallelograms of some sort. After all, this has to go into a .tif/.png/.hdf/etc container at the end of the day. There are a lot of advantages to storing data in a form that's close to that.
{kind=link}